Time-series Classification Methods Review and Applications to Power Systems Data
A Brief Survey of Time Series Nomenclature Algorithms
Dedicated algorithms specially designed for classifying fourth dimension series

A common task for time series machine learning is classification. Given a set of time series with class labels, tin can we railroad train a model to accurately predict the course of new fourth dimension series?
There are many algorithms defended to time series nomenclature! This means you don't have wrangle your data into a scikit-learn classifier or to plough to deep learning to solve every fourth dimension serial classification task.
In this article, I volition innovate 5 categories of time serial nomenclature algorithms with details of specific algorithms. These specific algorithms have been shown to perform better on average than a baseline classifier (KNN) over a large number of different datasets [i].
- Altitude-based (KNN with dynamic fourth dimension warping)
- Interval-based (TimeSeriesForest)
- Dictionary-based (Boss, cBOSS)
- Frequency-based (RISE — like TimeSeriesForest simply with other features)
- Shapelet-based (Shapelet Transform Classifier)
I conclude with brief guidance on selecting an appropriate algorithm.
The algorithms described in this article accept been implemented in the sktime python parcel.
Why dedicated algorithms for time series?
Time serial classification algorithms tend to perform ameliorate than tabular classifiers on time series classification problems.
A common, but problematic solution to fourth dimension serial classification is to treat each time point as a separate feature and directly use a standard learning algorithm (e.thou. scikit-larn classifiers). In this arroyo, the algorithm ignores data contained in the fourth dimension order of the data. If the characteristic gild were scrambled, the predictions wouldn't change.
It is also mutual to use deep learning to allocate time series. LSTMs and CNNs are capable of mining dynamical characteristics of time serial, hence their success. Withal neural networks have some challenges that brand them unsuitable for many classification tasks:
- Selecting an efficient compages
- Hyper-parameter tuning
- Limited data (neural networks demand many examples)
- Ho-hum to train
In spite of these challenges, there do exist specific neural network architectures for time series nomenclature. These take been implemented in the sktime-dl python package.
Foundational Concepts of Fourth dimension Series Classification
Fourth dimension Serial Transformations
Many time series specific algorithms are compositions of transformed time serial and conventional classification algorithms, such as those in scikit-learn.
Feature extraction is very diverse and complex.
Features tin can exist extracted globally (over the entire time series) or locally (over regular intervals/bins, random intervals, sliding windows of intervals, then on).
Serial can be transformed into primitive values (e.m. mean, standard deviation, slope) or into other series (e.m. Fourier transform, serial of fitted motorcar-regressive coefficients).
Last, transformations can one-dimensional or multi-dimensional.
Contracting
Contracting is a central concept used in most algorithms described in this commodity.
Simply stated, contracting limits the run time of an algorithm. Until the allotted time expires, the algorithm continues iterating to learn the given task.
Distance-Based Classification
These classifiers apply distance metrics to determine class membership.
One thousand-Nearest Neighbors (with Dynamic Time Warping) for Time Series
The popular k-nearest neighbors (KNN) algorithm tin exist adapted for time series past replacing the Euclidean distance metric with the dynamic fourth dimension warping (DTW) metric. DTW measures similarity between two sequences that may not marshal exactly in fourth dimension, speed, or length. (Click here for my explanation of DTW for time series clustering).
KNN with DTW is unremarkably used as a criterion for evaluating time serial classification algorithms because it is simple, robust, and does not require extensive hyperparameter tuning.
While useful, KNN with DTW requires a lot of space and time to compute. During nomenclature, the KNN-DTW compares each object with all the other objects in the training fix. Further, KNN provides limited information near why a series was assigned to a certain class.
KNN may also perform poorly with noisy serial — the noise in a serial may overpower subtle differences in shape that are useful for class bigotry [4].
Interval-based Classifiers
These classifiers base classification on data contained in various intervals of series.
Time Series Forest Classifier
A time series forest (TSF) classifier adapts the random forest classifier to series data.
- Dissever the series into random intervals, with random first positions and random lengths.
- Extract summary features (hateful, standard difference, and slope) from each interval into a single feature vector.
- Railroad train a decision tree on the extracted features.
- Repeat steps ane–3 until the required number of trees accept been built or time runs out.
New series are classified according to a majority vote of all the copse in the forest. (In a majority vote, the prediction is the course that is predicted by the virtually trees is the prediction of the forest).
Experimental studies take demonstrated that time series woods can outperform baseline competitors, such every bit nearest neighbors with dynamic time warping [1, 7].
Time series woods is also computationally efficient.
Last, fourth dimension series woods is an interpretable model. Time feature importance can be extracted from time serial forest, as shown in the sktime univariate time serial nomenclature demo.
Lexicon-Based Nomenclature
Dictionary-based classifiers first transform real-valued time series into a sequence of discrete "words". Nomenclature is so based on the distribution of the extracted symbolic words.
Lexicon classifiers all apply the same core process: A sliding window of length westward is run beyond a series. For each window, the numeric series is transformed into a "word" of length fifty. This discussion consists of α possible letters.
Handbag of SFA Symbols (Boss)
Discussion features for Dominate classifiers are extracted from series using the Symbolic Fourier Approximation (SFA) transformation:
- Calculate the Fourier transform of the window (the showtime term is ignored if normalization occurs)
- Discretize the get-go
lFourier terms into symbols to form a "word" using Multiple Coefficient Binning (MCB). MCB is a supervised algorithm that bins continuous time serial into a sequence of messages.
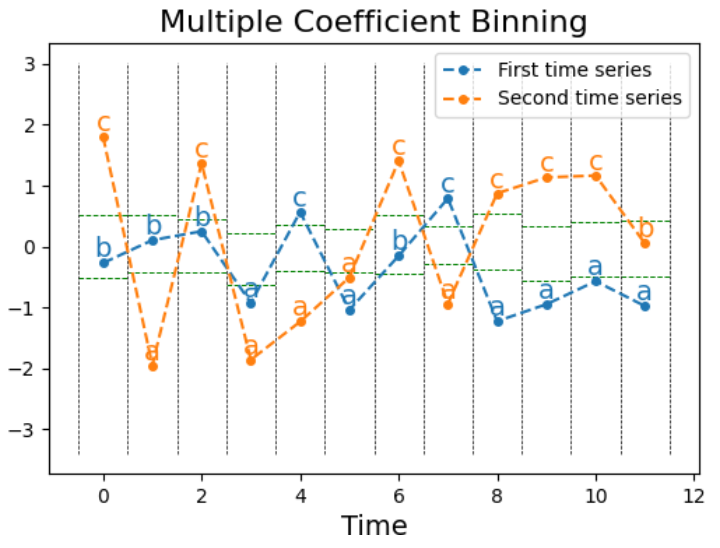
A lexicon of these words is constructed as the window slides, recording a count of each give-and-take's frequency. If the same give-and-take is produced by two or more than consecutive windows, the word volition just be counted once. When the sliding window has completed, the series is transformed into a histogram based on the lexicon.
Finally, any classifier can be trained on the word histograms extracted from the series.
The Boss Ensemble
The original BOSS algorithm is really an ensemble of the Dominate classifiers previously described. The Boss ensemble conducts grid-search across the parameters (fifty, α, w and p) of the private Boss classifier. (p controls whether the subseries is normalized.) The ensemble just retains the members whose accuracy is inside 92% accuracy of the best classifier.
The BOSS ensemble uses a nearest-neighbor algorithm as its classifier. The classifier uses a custom non-symmetric distance function: a partial Euclidian distance that only includes words contained in the test instance's histogram.
Due to searching over a large pre-defined parameter space, Dominate carries time overhead and risks instability in retention usage.
The Boss ensemble was the near accurate dictionary-based classifier in the Peachy Time Series Classification Bake-off paper [1].
Contractable Dominate (cBOSS)
The cBOSS algorithm is an guild of magnitude faster than BOSS. Compared to Boss, cBOSS had no meaning difference in accuracy on datasets in the UCR Classification Annal.
Instead of doing grid search beyond the full parameter space like Boss, cBOSS randomly samples from the parameter space without replacement. cBOSS then subsamples the data for each base classifier.
cBOSS improves the memory requirements of Boss by retaining a stock-still number of base classifiers, instead of retaining all classifiers above a given performance threshold. Last, cBOSS exponentially weights the contribution of each base of operations classifier according to train accuracy.
Frequency-based
Frequency-based classifiers rely on frequency data extracted from series.
Random Interval Spectral Ensemble (Rise)
Random Interval Spectral Ensemble, or Ascension, is a popular variant of time series forest.
Rising differs from fourth dimension series forest in two ways. First, it uses a single fourth dimension series interval per tree. 2d, information technology is trained using spectral features extracted from the series, instead of summary statistics.
Rise employ several series-to-serial feature extraction transformers, including:
- Fitted auto-regressive coefficients
- Estimated autocorrelation coefficients
- Power spectrum coefficients (the coefficients of the Fourier transform)
The Rising algorithm is straightforward:
- Select random interval of a series (length is a power of 2). (For the start tree, use the whole series)
- For the same interval on each series, employ the serial-to-serial feature extraction transformers (autoregressive coefficients, autocorrelation coefficients, and power spectrum coefficients)
- Class a new training set by concatenating the extracted features
- Train a decision tree classifier
- Ensemble 1–iv
Class probabilities are calculated every bit a proportion of base classifier votes. Rising controls the run time by creating an adaptive model of the time to build a unmarried tree. This is important for long serial (such equally sound), where very large intervals can hateful very few trees.
Shapelet-Based Classifiers
Shapelets are subsequences, or small sub-shapes of time serial that are representative of a form. They can exist used to find "phase-independent localised similarity between series within the same class" [i].
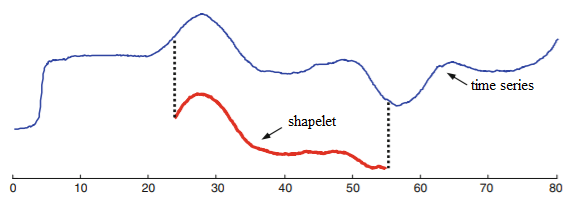
A single shapelet is an interval in a time series. The intervals in any series can be enumerated. For example, [1,two,iii,4] has 5 intervals: [one,2], [2,3], [3,iv], [1,two,3], [two,three,four].
Shapelet-based classifiers search for shapelets with discriminatory power.
These shapelet features tin then exist used to interpret a shapelet-based classifier — the presence of certain shapelets make ane class more likely than another.
Shapelet Transform Classifier
In the Shapelet Transform Classifier, the algorithm first identifies the pinnacle k shapelets in the dataset.
Next, g features for the new dataset are calculated. Each characteristic is computed every bit the distance of the series to each one of the thou southhapelets, with one cavalcade per shapelet.
Finally, any vector-based classification algorithm can exist applied to the shapelet-transformed dataset. In [ane], a weighted ensemble classifier was used. In [2], the authors just used a Rotation Woods classifier, a tree-based ensemble that constructs each tree on a subset of features transformed by PCA [5]. On average, rotation forest is the all-time classifier for problems with continuous features, as shown in [6] .
In sktime, a Random Forest classifier (500 trees) is used by default considering rotation forest is not all the same bachelor in python [eight].
How does the algorithm identify and select shapelets?
In sktime, the shapelet search process does not fully enumerate and evaluate all possible shapelets. Instead, it randomly searches for shapelets to evaluate.
Each shapelet considered is evaluated co-ordinate to data gain. The strongest not-overlapping shapelets are retained.
You tin specify the amount of time to search for shapelets before performing the shapelet transform. The default fourth dimension in sktime is 300 minutes.
Ensemble Classifiers
HIVE-COTE
The Hierarchical Vote Commonage of Transformation-based Ensembles (HIVE-COTE) is a meta ensemble built on the classifiers discussed previously.
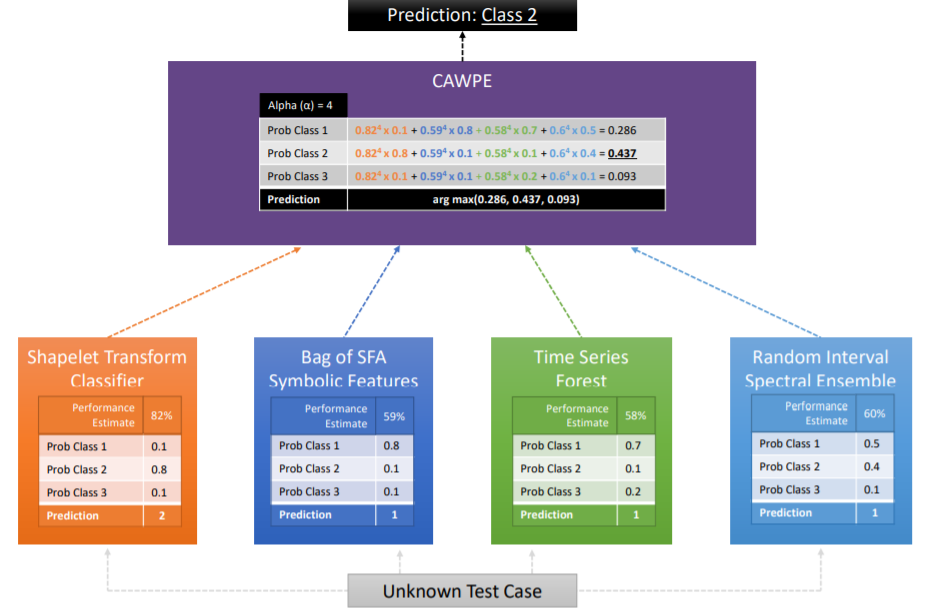
HIVE-COTE predictions are a weighted average of predictions produced past its members: shapelet transform classifier, BOSS, Time Serial Woods, and Ascension.
Each sub-classifier estimates the probability of each class. The command unit of measurement then combines these probabilities (CAPWE). The weights are assigned as the relative estimated quality of the classifier institute on the training information.
Which Classifier to Use?
There are three principal considerations when selecting a time series classifier: predictive accuracy, time/memory complication, and data representation.
With no data-specific information, start with ROCKET or HIVE-COTE. (ROCKET is a simple linear classifier based on random convolutional kernels — random length, weights, bias, dilation, and padding). The authors of [2] argue that "with no expert noesis to the reverse, the well-nigh authentic algorithm design is to ensemble classifiers congenital on unlike representations." On average, ROCKET is not worse than HIVE-COTE and is much faster.
Shapelet-based classifiers volition be improve when the all-time characteristic might be the presence or absence of a phase-independent pattern in a series.
Dictionary-based (Boss) or frequency-based (RISE) classifiers volition exist improve when y'all tin can discriminate using the frequency of a pattern.
A Last Word
If you enjoyed this article, please follow me for more content on data scientific discipline topics! I plan to go on writing about time series classification, clustering, and regression.
Thanks to Markus Loning for his feedback on this article and to Anthony Bagnall for guidance on model selection.
References
[1] Bagnall, Anthony, et al. "The great time series nomenclature bake off: a review and experimental evaluation of contempo algorithmic advances." Data Mining and Knowledge Discovery 31.3 (2017): 606–660. and
[ii] Bagnall, Anthony, et al. "A tale of 2 toolkits, written report the tertiary: on the usage and performance of HIVE-COTE v1.0." 2019
[3] Fawaz, Hassan Ismail, et al. "Deep learning for time series classification: a review." Data Mining and Knowledge Discovery 33.iv (2019): 917–963.
[four] L. Ye and E. Keogh. Time serial shapelets: a novel technique that allows accurate, interpretable and fast classification. Data Mining and Cognition Discovery, 22(1–2):149–182, 2011.
[5] Rodriguez, J, et al. Rotation Forest: A New Classifier Ensemble Method. November 2006. IEEE Transactions on Pattern Analysis and Machine Intelligence 28(x):1619–30. DOI: 10.1109/TPAMI.2006.211
[6] Bagnall, Anthony, et al. "Is rotation forest the all-time classifier for problems with continuous features?" 2018. arXiv: 1809.06705.
[seven] Deng, H, et al. "A Time Series Forest for Nomenclature and Feature Extraction." Information Sciences 239: 142–153 (2013).
[eight] Bagnall, Anthony, et al. "A tale of 2 toolkits, report the kickoff: benchmarking time series nomenclature algorithms for definiteness and efficiency." 2019.
[9] Dempster A, Petitjean F, Webb GI (2019) ROCKET: Exceptionally fast and accurate fourth dimension serial classification using random convolutional kernels. arXiv:1910.13051
Dictionary based fourth dimension series classification in sktime
sktime's Univariate Time Serial Nomenclature Tutorial
Source: https://towardsdatascience.com/a-brief-introduction-to-time-series-classification-algorithms-7b4284d31b97
0 Response to "Time-series Classification Methods Review and Applications to Power Systems Data"
Post a Comment